两个模型都没有成功的主要原因是:对于同一个 X 值存在多个不同的 y 值……更具体地说,对于同一个 X 似乎存在不止一个可能的 y 分布。回归模型只是试图找到最小化误差的最优函数,并没有考虑到密度的混合,所以 中间的那些X没有唯一的Y解,它们有两种可能的解,所以导致了以上的问题。
现在让我们尝试一个 MDN 模型,这里已经实现了一个快速且易于使用的“fit-predict”、“sklearn alike”自定义 python MDN 类。如果您想自己使用它,这是 python 代码的链接(请注意:这个 MDN 类是实验性的,尚未经过广泛测试):https://github.com/CoteDave/blog/blob/master/Made%20easy/MDN%20regression/mdn_model.py
为了能够使用这个类,有 sklearn、tensorflow probability、Tensorflow < 2、umap 和 hdbscan(用于自定义可视化类 功能)。
EPOCHS = 10000
BATCH_SIZE=len(X)
model = MDN(n_mixtures = -1,
dist = 'laplace',
input_neurons = 1000,
hidden_neurons = [25],
gmm_boost = False,
optimizer = 'adam',
learning_rate = 0.001,
early_stopping = 250,
tf_mixture_family = True,
input_activation = 'relu',
hidden_activation = 'leaky_relu')
model.fit(X, y, epochs = EPOCHS, batch_size = BATCH_SIZE)
类的参数总结如下:
n_mixtures:MDN 使用的分布混合数。如果设置为 -1,它将使用高斯混合模型 (GMM) 和 X 和 y 上的 HDBSCAN 模型“自动”找到最佳混合数。
dist:在混合中使用的分布类型。目前,有两种选择;“正常”或“拉普拉斯”。(基于一些实验,拉普拉斯分布比正态分布更好的结果)。
input_neurons:在MDN的输入层中使用的神经元数量
hidden_neurons:MDN的 隐藏层架构。每个隐藏层的神经元列表。此参数使您能够选择隐藏层的数量和每个隐藏层的神经元数量。
gmm_boost:布尔值。如果设置为 True,将向数据集添加簇特征。
optimizer:要使用的优化算法。
learning_rate:优化算法的学习率
early_stopping:避免训练时过拟合。当指标在给定数量的时期内没有变化时,此触发器将决定何时停止训练。
tf_mixture_family:布尔值。如果设置为 True,将使用 tf_mixture 系列(推荐):Mixture 对象实现批量混合分布。
input_activation:输入层的激活函数
hidden_activation:隐藏层的激活函数
现在 MDN 模型已经拟合了数据,从混合密度分布中采样并绘制概率密度函数:
model.plot_distribution_fit(n_samples_batch = 1)
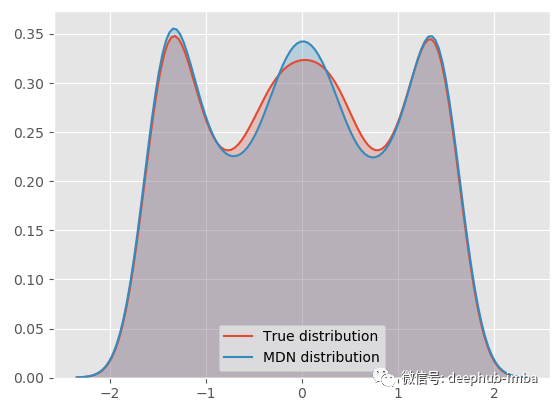
我们的 MDN 模型非常适合真正的一般分布!下面将最终的混合分布分解为每个分布,看看它的样子:
model.plot_all_distribution_fit(n_samples_batch = 1)
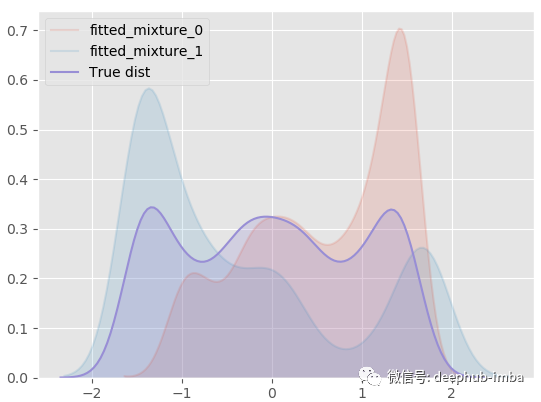
使用学习到的混合分布再次采样一些 Y 数据,生成的样本与真实样本进行对比:
model.plot_samples_vs_true(X, y, alpha = 0.2)
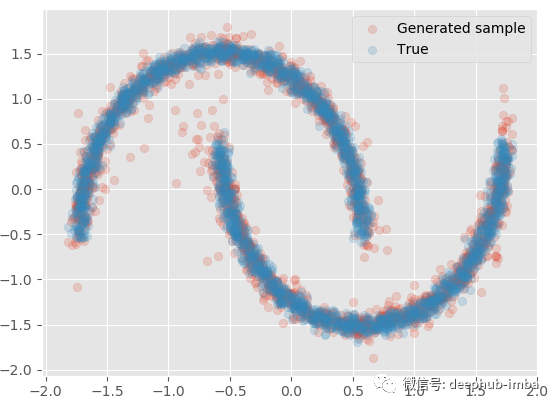
与实际的数据非常接近,如果,给定 X还可以生成多批样本以生成分位数、均值等统计信息:
generated_samples = model.sample_from_mixture(X, n_samples_batch = 10)
generated_samples
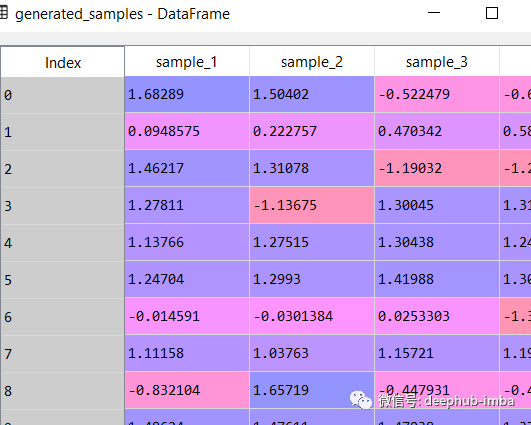
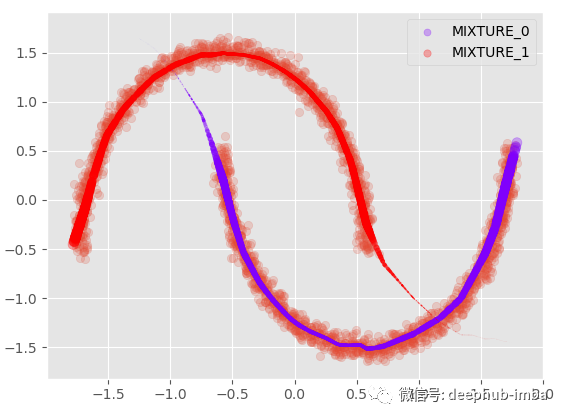
绘制每个学习分布的平均值,以及它们各自的混合权重 (pi):
plt.scatter(X, y, alpha = 0.2)
model.plot_predict_dist(X, with_weights = True, size = 250)
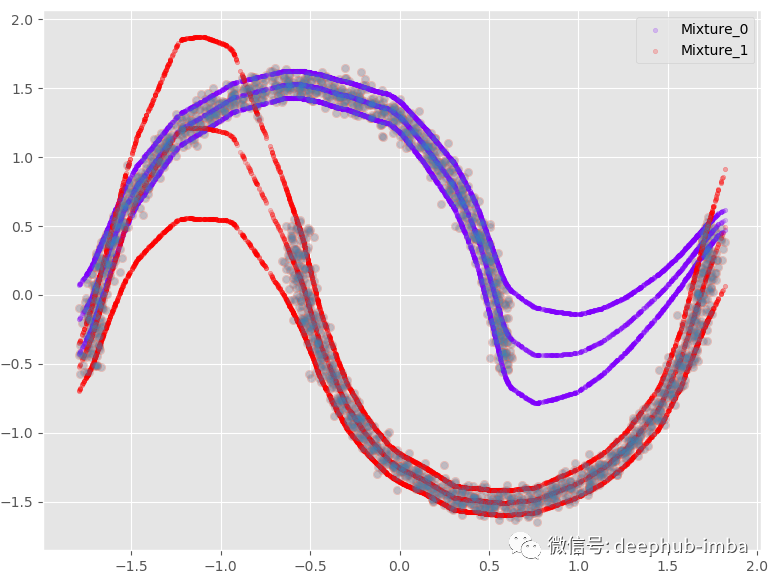
有每个分布的均值和标准差,还可以绘制带有完整不确定性;假设我们以 95% 的置信区间绘制平均值:
plt.scatter(X, y, alpha = 0.2)
model.plot_predict_dist(X, q = 0.95, with_weights = False)
将分布混合在一起,当对同一个 X 有多个 y 分布时,我们使用最高 Pi 参数值选择最可能的混合:
Y_preds = 对于每个 X,选择具有最大概率/权重(Pi 参数)的分布的 Y 均值
plt.scatter(X, y, alpha = 0.3)
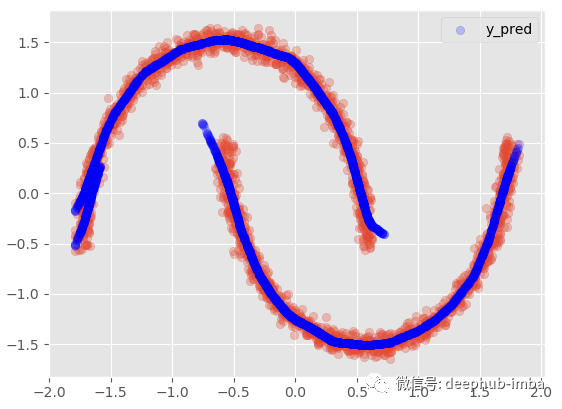
model.plot_predict_best(X)
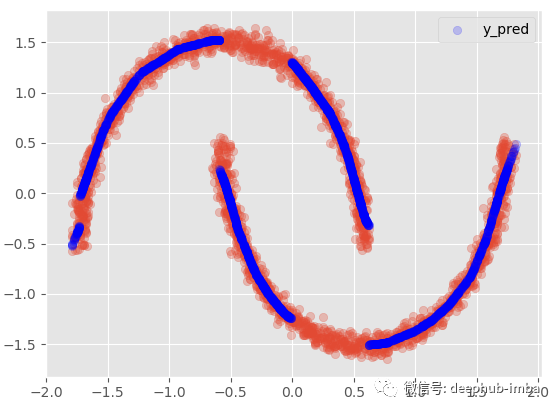
这种方式表现得并不理想,因为在数据中显然有两个不同的簇重叠,密度几乎相等。使得误差将高于标准回归模型。这也意味着数据集中可能缺少一个可以帮助避免集群在更高维度上重叠重要特征。
我们还可以选择使用 Pi 参数和所有分布的均值混合分布:
· Y_preds = (mean_1 * Pi1) + (mean_2 * Pi2)
plt.scatter(X, y, alpha = 0.3)
model.plot_predict_mixed(X)
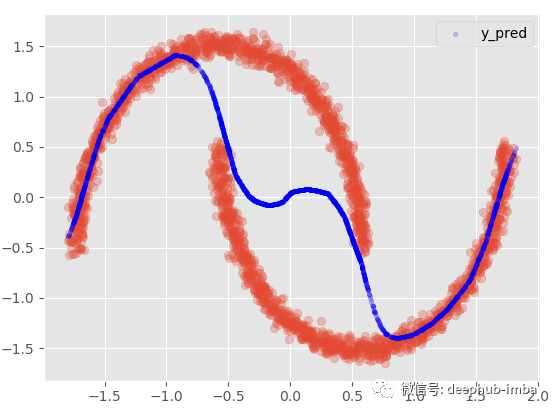
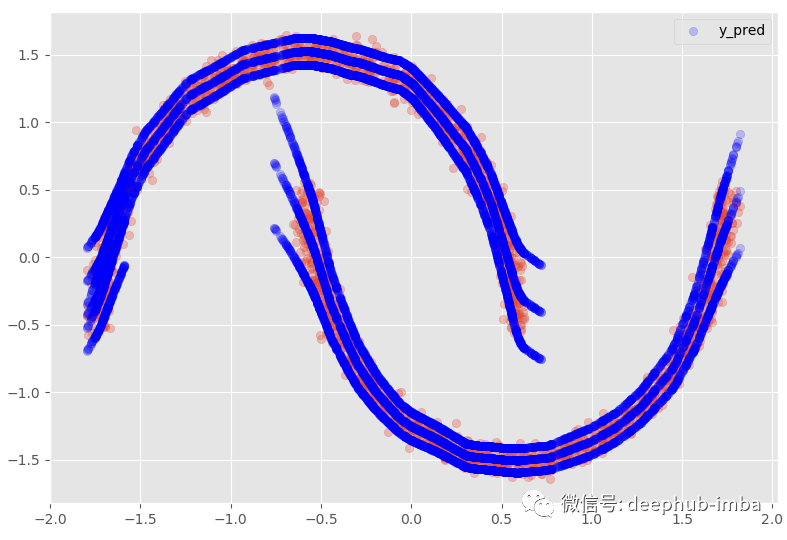
如果我们添加 95 置信区间: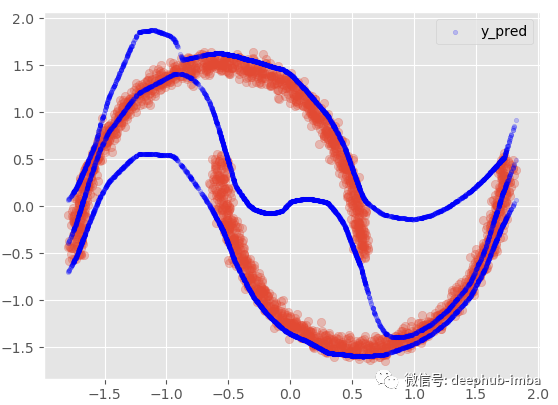
这个选项提供了与非线性回归模型几乎相同的结果,混合所有内容以最小化点和函数之间的距离。在这个非常特殊的情况下,我最喜欢的选择是假设在数据的某些区域,X 有多个 Y,而在其他区域;仅使用其中一种混合。:
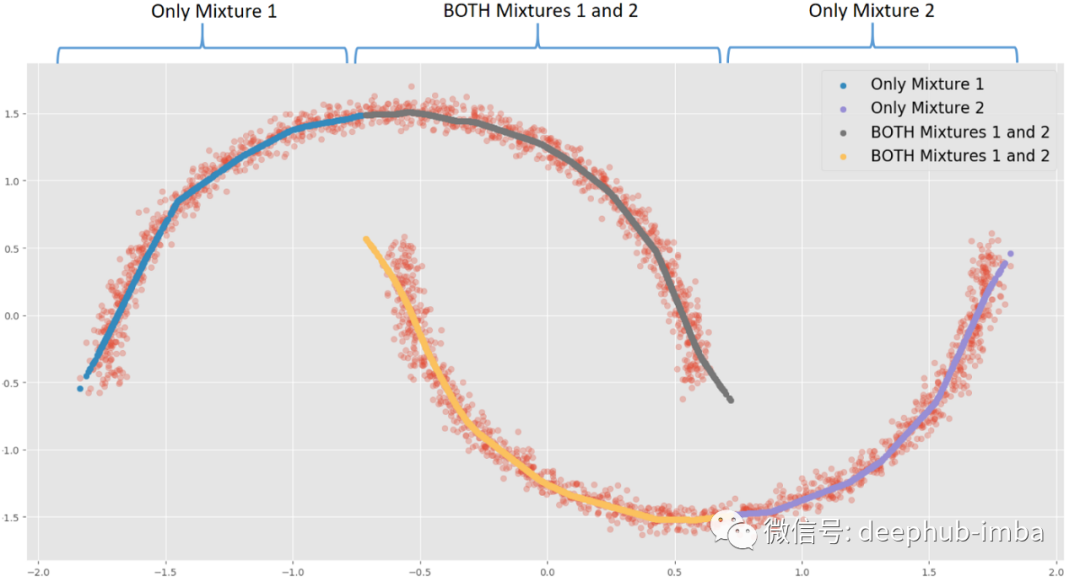
例如,当 X = 0 时,每种混合可能有两种不同的 Y 解。当 X = -1.5 时,混合 1 中存在唯一的 Y 解决方案。根据用例或业务上下文,当同一个 X 存在多个解决方案时,可以触发操作或决策。
这个选项得含义是当存在重叠分布时(如果两个混合概率都 >= 给定概率阈值),行将被复制:
plt.scatter(X, y, alpha = 0.3)
model.plot_predict_with_overlaps(X)
使用 95% 置信区间:
数据集行从 2500 增加到了 4063,最终预测数据集如下所示: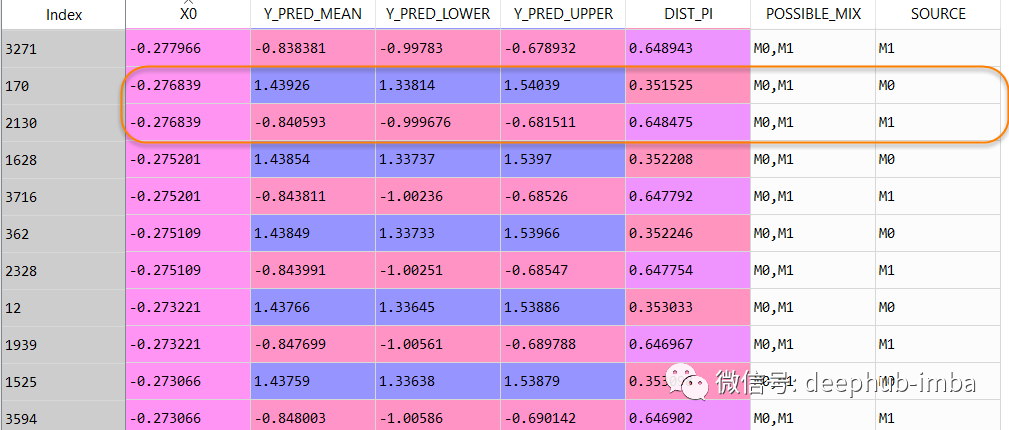
在这个数据表中,当 X = -0.276839 时,Y 可以是 1.43926(混合_0 的概率为 0.351525),但也可以是 -0.840593(混合_1 的概率为 0.648475)。
具有多个分布的实例还提供了重要信息,即数据中正在发生某些事情,并且可能需要更多分析。可能是一些数据质量问题,或者可能表明数据集中缺少一个重要特征!
“交通场景预测是可以使用混合密度网络的一个很好的例子。在交通场景预测中,我们需要一个可以表现出的行为分布——例如,一个代理可以左转、右转或直行。因此,混合密度网络可用于表示它学习的每个混合中的“行为”,其中行为由概率和轨迹组成((x,y)坐标在未来某个时间范围内)。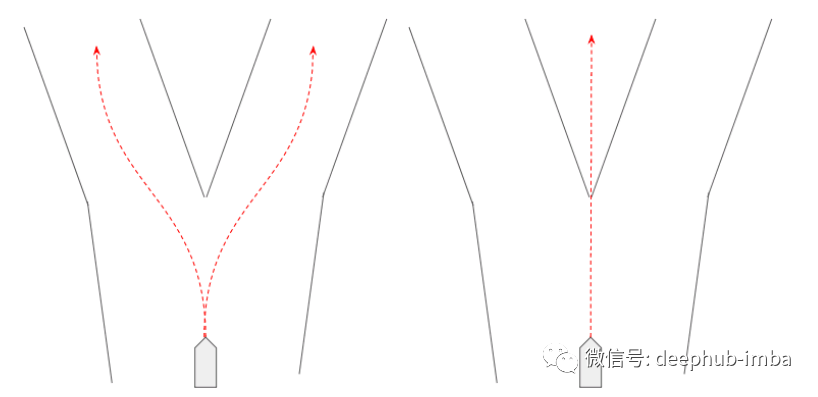
示例2:具有MDN 的多变量回归
最后MDN 在多元回归问题上表现良好吗?
我们将使用以下的数据集: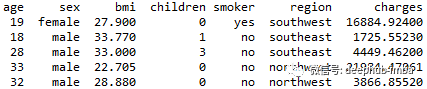
年龄:主要受益人的年龄
性别:保险承包商性别,女,男
bmi:体重指数,提供对身体的了解,相对于身高相对较高或较低的体重,使用身高与体重之比的体重客观指数(kg / m ^ 2),理想情况下为18.5到24.9
子女:健康保险覆盖的子女人数/受抚养人人数
吸烟者:吸烟
地区:受益人在美国、东北、东南、西南、西北的居住区。
费用:由健康保险计费的个人医疗费用。这是我们要预测的目标
问题陈述是:能否准确预测保险费用(收费)?
现在,让我们导入数据集:
"""
#################
# 2-IMPORT DATA #
#################
"""
dataset = pd.read_csv('insurance_clean.csv', sep = ';')
##### BASIC FEATURE ENGINEERING
dataset['age2'] = dataset['age'] * dataset['age']
dataset['BMI30'] = np.where(dataset['bmi'] > 30, 1, 0)
dataset['BMI30_SMOKER'] = np.where((dataset['bmi'] > 30) & (dataset['smoker_yes'] == 1), 1, 0)
"""
######################
# 3-DATA PREPARATION #
######################
"""
###### SPLIT TRAIN TEST
from sklearn.model_selection import train_test_split
X = dataset[dataset.columns.difference(['charges'])]
y = dataset[['charges']]
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.25,
stratify = X['smoker_yes'],
random_state=0)
test_index = y_test.index.values
train_index = y_train.index.values
features = X.columns.tolist()
##### FEATURE SCALING
from sklearn.preprocessing import StandardScaler
x_scaler = StandardScaler()
y_scaler = StandardScaler()
X_train = x_scaler.fit_transform(X_train)
#X_calib = x_scaler.transform(X_calib)
X_test = x_scaler.transform(X_test)
y_train = y_scaler.fit_transform(y_train)
#y_calib = y_scaler.transform(y_calib)
y_test = y_scaler.transform(y_test)
y_test_scaled = y_test.copy()
数据准备完整可以开始训练了
EPOCHS = 10000
BATCH_SIZE=len(X_train)
model = MDN(n_mixtures = -1, #-1
dist = 'laplace',
input_neurons = 1000, #1000
hidden_neurons = [], #25
gmm_boost = False,
optimizer = 'adam',
learning_rate = 0.0001, #0.00001
early_stopping = 200,
tf_mixture_family = True,
input_activation = 'relu',
hidden_activation = 'leaky_relu')
model.fit(X_train, y_train, epochs = EPOCHS, batch_size = BATCH_SIZE)
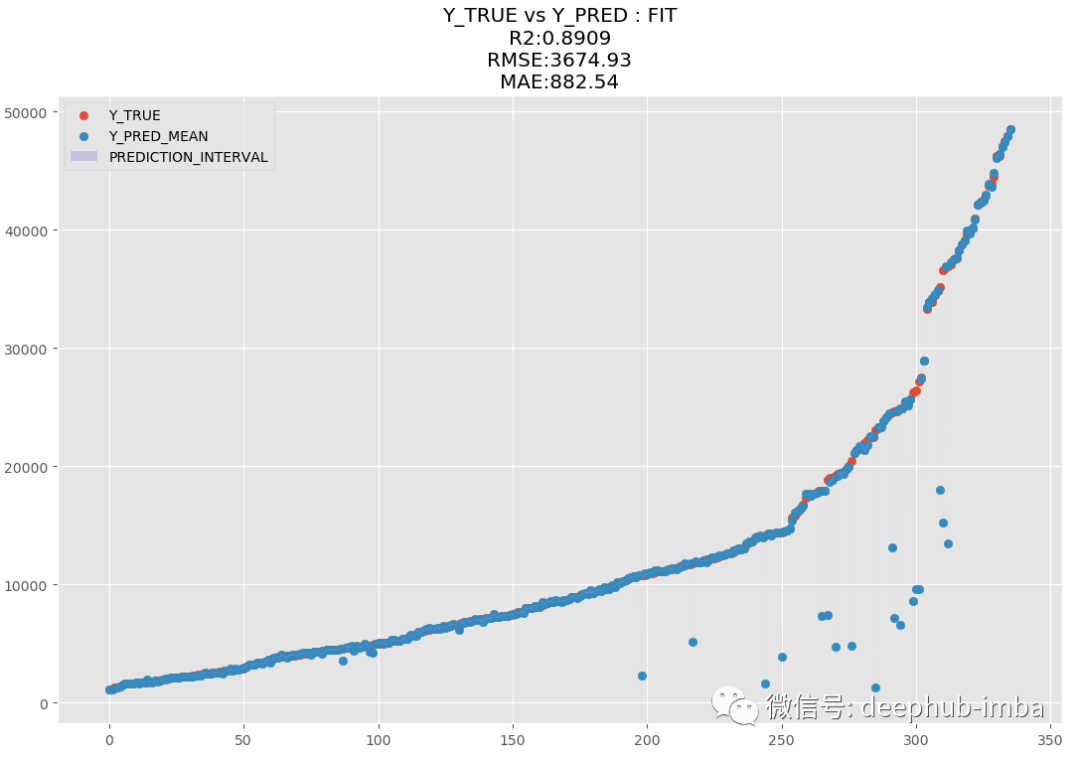
训练完成后使用“最佳混合概率(Pi 参数)策略”预测测试数据集并绘制结果(y_pred vs y_test):
y_pred = model.predict_best(X_test, q = 0.95, y_scaler = y_scaler)
model.plot_pred_fit(y_pred, y_test, y_scaler = y_scaler)
model.plot_pred_vs_true(y_pred, y_test, y_scaler = y_scaler)
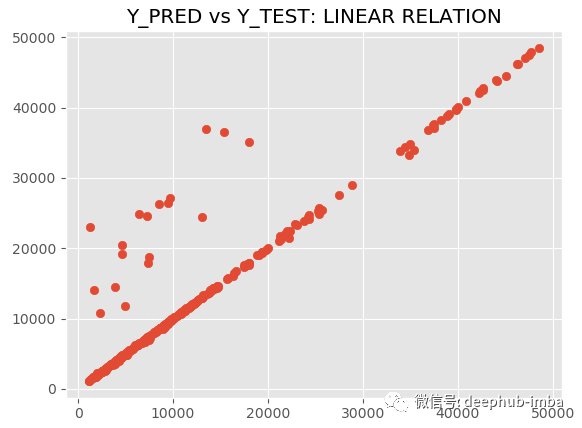
R2 为 89.09,MAE 为 882.54,MDN太棒了,让我们绘制拟合分布与真实分布的图来进行对比:
model.plot_distribution_fit(n_samples_batch = 1)
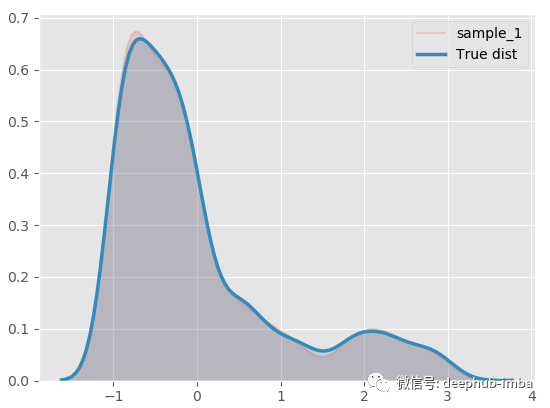
几乎一模一样!分解混合模型,看看什么情况: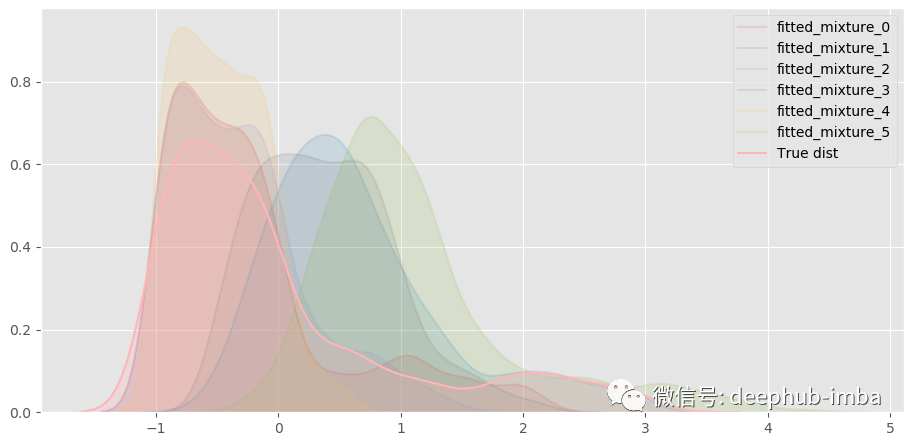
一共混合了六种不同的分布。
从拟合的混合模型生成多变量样本(应用 PCA 以在 2D 中可视化结果):
model.plot_samples_vs_true(X_test, y_test, alpha = 0.35, y_scaler = y_scaler)
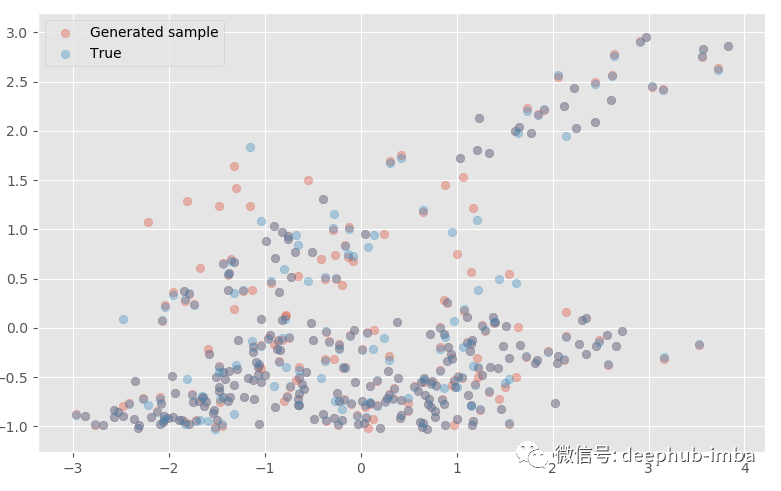
生成的样本与真实样本非常接近!如果我们愿意,还可以从每个分布中进行预测:
y_pred_dist = model.predict_dist(X_test, q = 0.95, y_scaler = y_scaler)
y_pred_dist
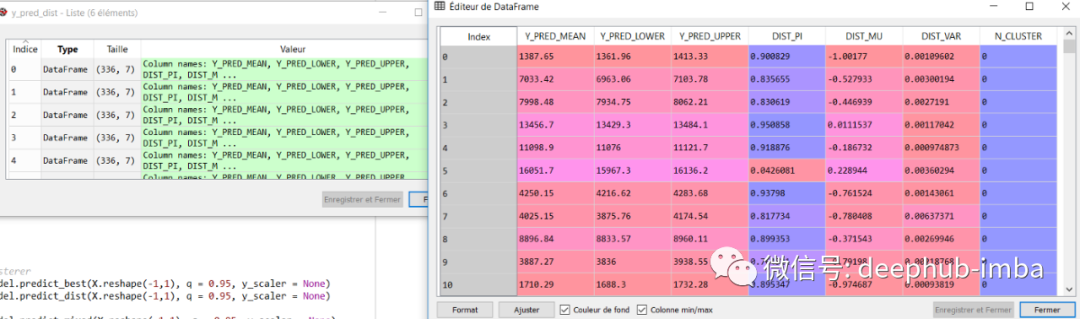
总结
与线性或非线性经典 ML 模型相比,MDN 在单变量回归数据集中表现出色,其中两个簇相互重叠,并且 X 可能有多个 Y 输出。
MDN 在多元回归问题上也做得很好,可以与 XGBoost 等流行模型竞争
MDN 是 ML 中的一款出色且独特的工具,可以解决其他模型无法解决的特定问题(能够从混合分布中获得的数据中学习)
随着 MDN 学习分布,还可以通过预测计算不确定性或从学习的分布中生成新样本
本文的代码非常的多,这里是完整的notebook,可以直接下载运行:
https://github.com/CoteDave/blog/blob/master/Made%20easy/MDN%20regression/Made%20easy%20-%20MDN%20regression.ipynb
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。