来源:DeepHub IMBA
大多数人都熟悉如何在图像、文本或表格数据上运行数据科学项目。但处理音频数据的样例非常的少见。在本文中,将介绍如何在机器学习的帮助下准备、探索和分析音频数据。简而言之:与其他的形式(例如文本或图像)类似我们需要将音频数据转换为机器可识别的格式。
音频数据的有趣之处在于您可以将其视为多种不同的模式:
可以提取高级特征并分析表格数据等数据。
可以计算频率图并分析图像数据等数据。
可以使用时间敏感模型并分析时间序列数据等数据。
可以使用语音到文本模型并像文本数据一样分析数据。
在本文中,我们将介绍前三种方法。首先看看音频数据的实际样子。
音频数据的格式
虽然有多个 Python 库可以处理音频数据,但我们推荐使用 librosa。让我们加载一个 MP3 文件并绘制它的内容。
# Import librosaimport librosa
# Loads mp3 file with a specific sampling rate, here 16kHzy, sr = librosa.load("c4_sample-1.mp3", sr=16_000)
# Plot the signal stored in 'y'from matplotlib import pyplot as pltimport librosa.display
plt.figure(figsize=(12, 3))plt.title("Audio signal as waveform")librosa.display.waveplot(y, sr=sr);
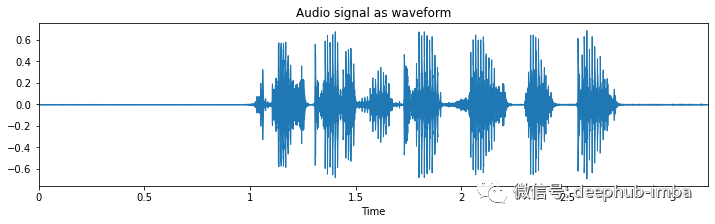
这里看到的是句子的波形表示。
1. 波形 - 信号的时域表示
之前称它为时间序列数据,但现在我们称它为波形? 当只看这个音频文件的一小部分时,这一点变得更加清晰。下图显示了与上面相同的内容,但这次只有 62.5 毫秒。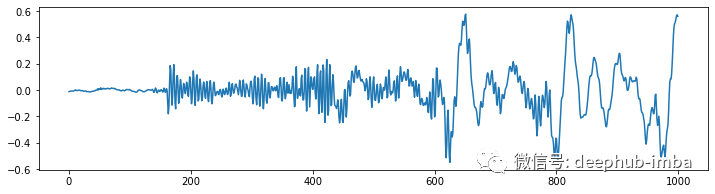
我们看到的是一个时间信号,它以不同的频率和幅度在值 0 附近振荡。该信号表示气压随时间的变化,或扬声器膜(或耳膜)的物理位移 . 这就是为什么这种对音频数据的描述也称为波形的原因。
频率是该信号振荡的速度。低频例如 60 Hz 可能是低音吉他的声音,而鸟儿的歌声可能是 8000 Hz 的更高频率。我们人类语言通常介于两者之间。
要知道这个信号在单位时间内从连续信号中提取并组成离散信号的采样个数,我们使用赫兹(Hz)来表示每秒的采样个数。16'000 或 16k Hz表示美标采集了16000次。我们在上图中可以看到的 1'000 个时间点代表了 62.5 毫秒(1000/16000 = 0.0625)的音频信号。
2. 傅里叶变换——信号的频域表示
虽然之前的可视化可以告诉我们什么时候发生了(即 2 秒左右似乎有很多波形信号),但它不能真正告诉我们它发生的频率。因为波形向我们显示了有关时间的信息,所以该信号也被称为信号的时域表示。
可以使用快速傅立叶变换,反转这个问题并获得关于存在哪些频率的信息,同时丢弃掉关于时间的信息。在这种情况下,信号表示被称为信号的频域表示。
让我们看看之前的句子在频域中的表现。
import scipyimport numpy as np
# Applies fast fourier transformation to the signal and takes absolute valuesy_freq = np.abs(scipy.fftpack.fft(y))
# Establishes all possible frequency# (dependent on the sampling rate and the length of the signal)f = np.linspace(0, sr, len(y_freq))
# Plot audio signal as frequency information.plt.figure(figsize=(12, 3))plt.semilogx(f[: len(f) // 2], y_freq[: len(f) // 2])plt.xlabel("Frequency (Hz)")plt.show();
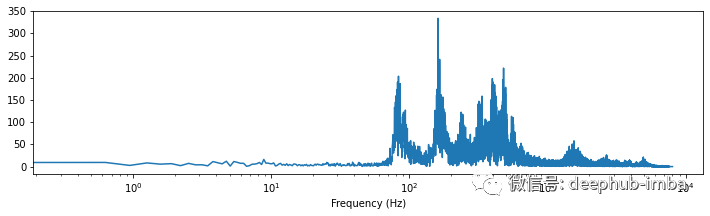
可以在此处看到大部分信号在 ~100 到 ~1000 Hz 之间(即 10² 到 10³ 之间)。另外,似乎还有一些从 1'000 到 10'000 Hz 的内容。
3. 频谱图
我们并不总是需要决定时域或频域。使用频谱图同时表示这两个领域中的信息,同时将它们的大部差别保持在最低限度。有多种方法可以创建频谱图,但在本文中将介绍常见的三种。
3a 短时傅里叶变换 (STFT)
这是之前的快速傅立叶变换的小型改编版本,即短时傅立叶变换 (STFT), 这种方式是以滑动窗口的方式计算多个小时间窗口(因此称为“短时傅立叶”)的 FFT。
import librosa.display
# Compute short-time Fourier Transformx_stft = np.abs(librosa.stft(y))
# Apply logarithmic dB-scale to spectrogram and set maximum to 0 dBx_stft = librosa.amplitude_to_db(x_stft, ref=np.max)
# Plot STFT spectrogramplt.figure(figsize=(12, 4))librosa.display.specshow(x_stft, sr=sr, x_axis="time", y_axis="log")plt.colorbar(format="%+2.0f dB")plt.show();
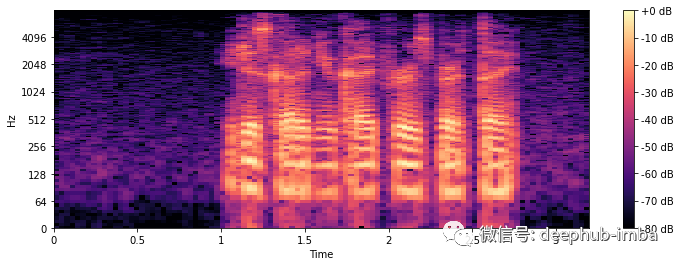
与所有频谱图一样,颜色代表在给定时间点给定频率的量(响度/音量)。+0dB 是最响亮的,-80dB 接近静音。在水平 x 轴上我们可以看到时间,而在垂直 y 轴上我们可以看到不同的频率。
3b 梅尔谱图
作为 STFT 的替代方案,还可以计算基于 mel 标度的梅尔频谱图。这个尺度解释了我们人类感知声音音高的方式。计算 mel 标度,以便人类将由 mel 标度中的 delta 隔开的两对频率感知为具有相同的感知差异。
梅尔谱图的计算与 STFT 非常相似,主要区别在于 y 轴使用不同的刻度。
# Compute the mel spectrogramx_mel = librosa.feature.melspectrogram(y=y, sr=sr)
# Apply logarithmic dB-scale to spectrogram and set maximum to 0 dBx_mel = librosa.power_to_db(x_mel, ref=np.max)
# Plot mel spectrogramplt.figure(figsize=(12, 4))librosa.display.specshow(x_mel, sr=sr, x_axis="time", y_axis="mel")plt.colorbar(format="%+2.0f dB")plt.show();
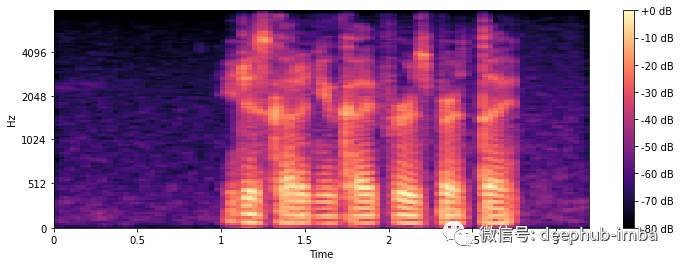
与 STFT 的区别可能不太明显,但如果仔细观察,就会发现在 STFT 图中,从 0 到 512 Hz 的频率在 y 轴上占用的空间比在 mel 图中要大得多。
3c 梅尔频率倒谱系数 (MFCC)
梅尔频率倒谱系数 (MFCC) 是上面梅尔频谱图的替代表示。MFCC 相对于 梅尔谱图的优势在于特征数量相当少(即独特的水平线标度),通常约为 20。
由于梅尔频谱图更接近我们人类感知音高的方式,并且 MFCC 只有少数几个分量特征,所以大多数机器学习从业者更喜欢 使用MFCC 以“图像方式”表示音频数据。但是对于某些问题,STFT、mel 或波形表示可能会更好。
让我们继续计算 MFCC 并绘制它们。
# Extract 'n_mfcc' numbers of MFCCs components (here 20)x_mfccs = librosa.feature.mfcc(y, sr=sr, n_mfcc=20)
# Plot MFCCsplt.figure(figsize=(12, 4))librosa.display.specshow(x_mfccs, sr=sr, x_axis="time")plt.colorbar()plt.show();

数据清洗
现在我们更好地理解了音频数据的样子,让我们可视化更多示例。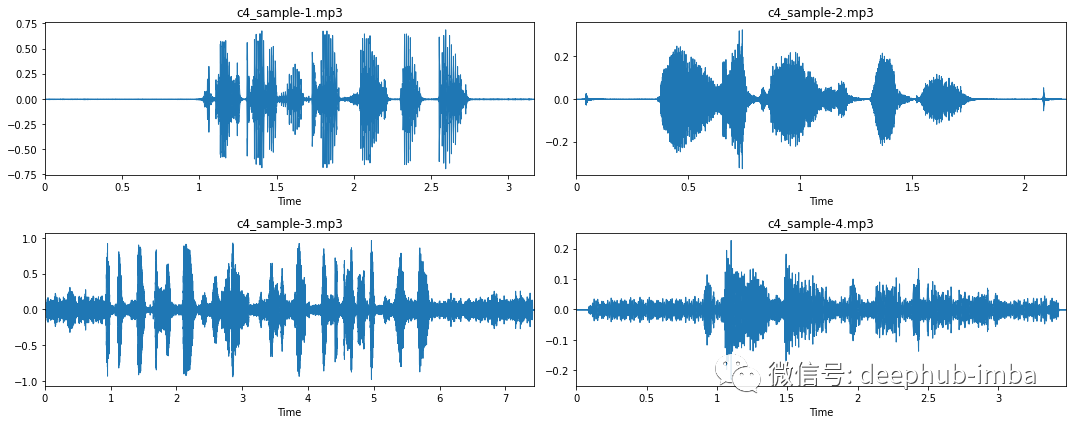
在这四个示例中,我们可以收集到有关此音频数据集的更多问题:
大多数录音在录音的开头和结尾都有一段较长的静默期(示例 1 和示例 2)。这是我们在“修剪”时应该注意的事情。
在某些情况下,由于按下和释放录制按钮,这些静音期会被“点击”中断(参见示例 2)。
一些录音没有这样的静音阶段,即一条直线(示例 3 和 4)。
在收听这些录音时,有大量背景噪音。
为了更好地理解这在频域中是如何表示的,让我们看一下相应的 STFT 频谱图。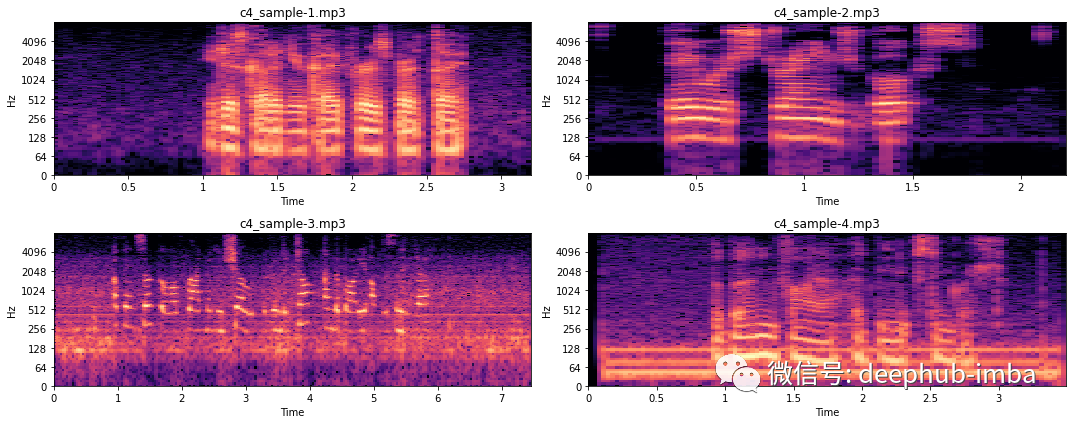
当听录音时,可以观察到样本 3 具有覆盖多个频率的不同背景噪声,而样本 4 中的背景噪声相当恒定。这也是我们在上图中看到的。样本 3 在整个过程中都非常嘈杂,而样本 4 仅在几个频率上(即粗水平线)有噪声。我们不会详细讨论如何消除这种噪音,因为这超出了本文的范围。
但是让我们研究一下如何消除此类噪音并修剪音频样本的“捷径”。虽然使用自定义过滤函数的更手动的方法可能是从音频数据中去除噪声的最佳方法,但在我们的例子中,将推荐使用实用的 python 包 noisereduce。
import noisereduce as nrfrom scipy.io import wavfile
# Loop through all four samplesfor i in range(4):
# Load audio file fname = "c4_sample-%d.mp3" % (i + 1) y, sr = librosa.load(fname, sr=16_000)
# Remove noise from audio sample reduced_noise = nr.reduce_noise(y=y, sr=sr, stationary=False)
# Save output in a wav file as mp3 cannot be saved to directly wavfile.write(fname.replace(".mp3", ".wav"), sr, reduced_noise)
聆听创建的 wav 文件,可以听到噪音几乎完全消失了。虽然我们还引入了更多的代码,但总的来说我们的去噪方法利大于弊。
对于修剪步骤,可以使用 librosa 的 .effects.trim() 函数。每个数据集可能需要一个不同的 top_db 参数来进行修剪,所以最好进行测试,看看哪个参数值好用。在这个的例子中,它是 top_db=20。
# Loop through all four samplesfor i in range(4):
# Load audio file fname = "c4_sample-%d.wav" % (i + 1) y, sr = librosa.load(fname, sr=16_000)
# Trim signal y_trim, _ = librosa.effects.trim(y, top_db=20)
# Overwrite previous wav file wavfile.write(fname.replace(".mp3", ".wav"), sr, y_trim)
现在让我们再看一下清理后的数据。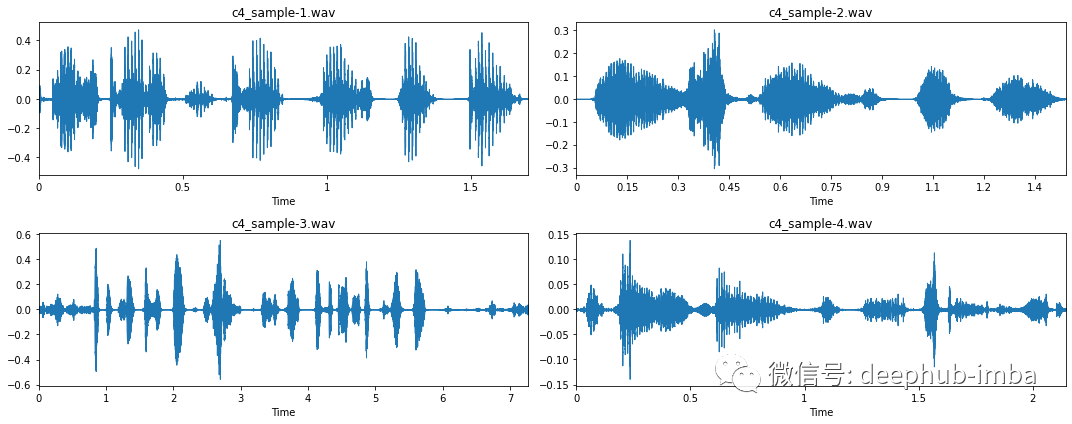
看样子好多了。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

