特征提取
数据是干净的,应该继续研究可以提取的特定于音频的特征了。
1. 开始检测
通过观察一个信号的波形,librosa可以很好地识别一个新口语单词的开始。
# Import librosa
import librosa
# Loads mp3 file with a specific sampling rate, here 16kHz
y, sr = librosa.load("c4_sample-1.mp3", sr=16_000)
# Plot the signal stored in 'y'
from matplotlib import pyplot as plt
import librosa.display
plt.figure(figsize=(12, 3))
plt.title("Audio signal as waveform")
librosa.display.waveplot(y, sr=sr);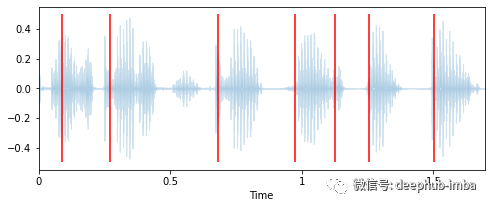
2. 录音的长度
与此密切相关的是录音的长度。录音越长,能说的单词就越多。所以计算一下录音的长度和单词被说出的速度。
duration = len(y) / sr
words_per_second = number_of_words / duration
print(f"""The audio signal is {duration:.2f} seconds long,
with an average of {words_per_second:.2f} words per seconds.""")
>>> The audio signal is 1.70 seconds long,
>>> with an average of 4.13 words per seconds.
3. 节奏
语言是一种非常悦耳的信号,每个人都有自己独特的说话方式和语速。因此,可以提取的另一个特征是说话的节奏,即在音频信号中可以检测到的节拍数。
# Computes the tempo of a audio recording
tempo = librosa.beat.tempo(y, sr, start_bpm=10)[0]
print(f"The audio signal has a speed of {tempo:.2f} bpm.")
>>> The audio signal has a speed of 42.61 bpm.
4. 基频
基频是周期声音出现时的最低频率。在音乐中也被称为音高。在之前看到的谱图图中,基频(也称为f0)是图像中最低的亮水平条带。而在这个基本音之上的带状图案的重复称为谐波。
为了更好地说明确切意思,下面提取基频,并在谱图中画出它们。
# Extract fundamental frequency using a probabilistic approach
f0, _, _ = librosa.pyin(y, sr=sr, fmin=10, fmax=8000, frame_length=1024)
# Establish timepoint of f0 signal
timepoints = np.linspace(0, duration, num=len(f0), endpoint=False)
# Plot fundamental frequency in spectrogram plot
plt.figure(figsize=(8, 3))
x_stft = np.abs(librosa.stft(y))
x_stft = librosa.amplitude_to_db(x_stft,ref=np.max)
librosa.display.specshow(x_stft, sr=sr, x_axis="time", y_axis="log")
plt.plot(timepoints, f0, color="cyan", linewidth=4)
plt.show();
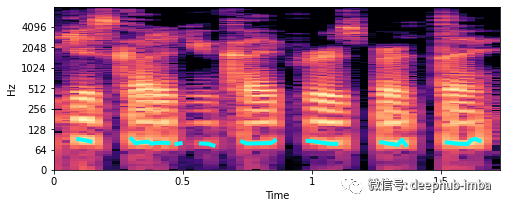
在 100 Hz 附近看到的绿线是基本频率。但是如何将其用于特征工程呢?可以做的是计算这个 f0 的具体特征。
# Computes mean, median, 5%- and 95%-percentile value of fundamental frequency
f0_values = [
np.nanmean(f0),
np.nanmedian(f0),
np.nanstd(f0),
np.nanpercentile(f0, 5),
np.nanpercentile(f0, 95),
]
print("""This audio signal has a mean of {:.2f}, a median of {:.2f}, a
std of {:.2f}, a 5-percentile at {:.2f} and a 95-percentile at {:.2f}.""".format(*f0_values))
>>> This audio signal has a mean of 81.98, a median of 80.46, a
>>> std of 4.42, a 5-percentile at 76.57 and a 95-percentile at 90.64.除以上说的技术以外,还有更多可以探索的音频特征提取技术,这里就不详细说明了。
音频数据集的探索性数据分析 (EDA)
现在我们知道了音频数据是什么样子以及如何处理它,让我们对它进行适当的 EDA。首先下载一个数据集Kaggle 的 Common Voice 。这个 14 GB 的大数据集只是来自 Mozilla 的 +70 GB 大数据集的一个小的快照。对于本文这里的示例,将只使用这个数据集的大约 9'000 个音频文件的子样本。
看看这个数据集和一些已经提取的特征。
1. 特征分布调查
目标类别年龄和性别的类别分布。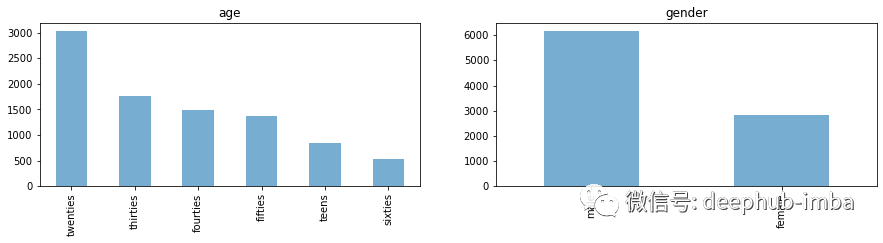
目标类别分布是不平衡的。
下一步,让我们仔细看看提取的特征的值分布。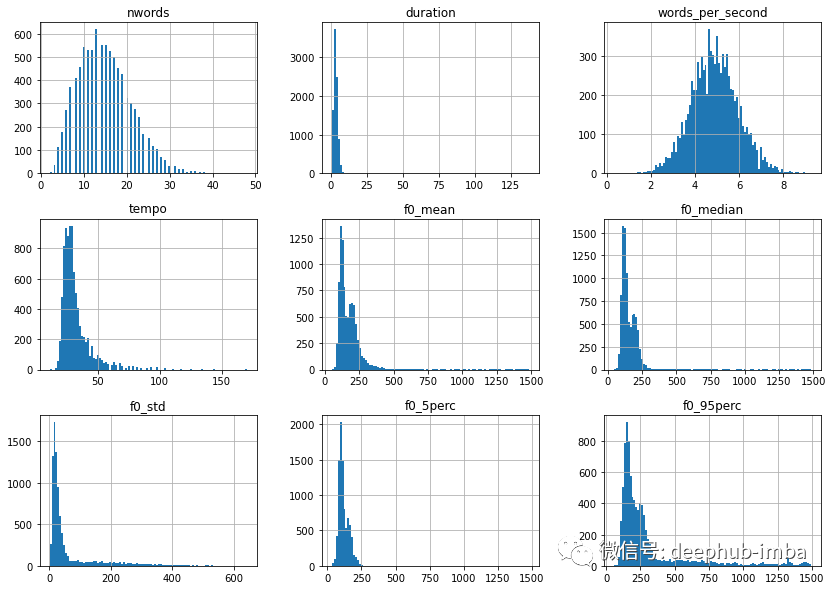
除了 words_per_second,这些特征分布中的大多数都是右偏的,因此可以从对数转换中获益。
import numpy as np # Applies log1p on features that are not age, gender, filename or words_per_second df = df.apply( lambda x: np.log1p(x) if x.name not in ["age", "gender", "filename", "words_per_second"] else x) # Let's look at the distribution once more df.drop(columns=["age", "gender", "filename"]).hist( bins=100, figsize=(14, 10)) plt.show();
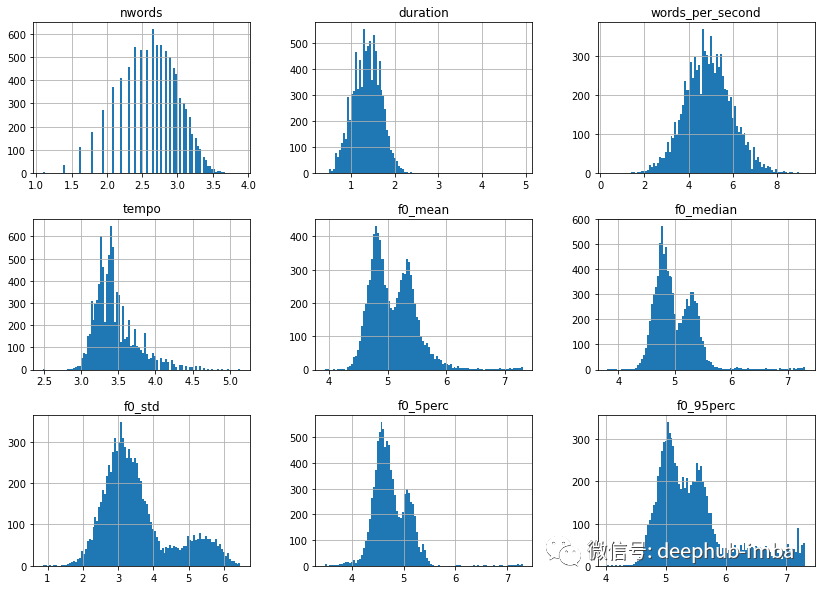
好多了,但有趣的是 f0 特征似乎都具有双峰分布。让我们绘制与以前相同的内容,但这次按性别分开。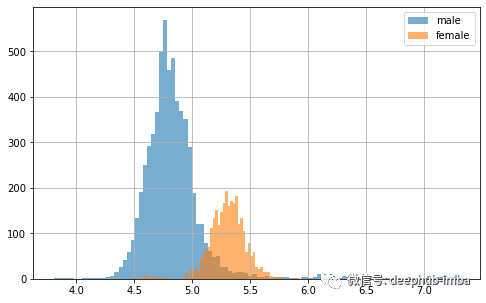
正如怀疑的那样,这里似乎存在性别效应!但也可以看到,一些 f0 分数(这里特别是男性)比应有的低和高得多。由于特征提取不良,这些可能是异常值。仔细看看下图的所有数据点。
# Plot sample points for each feature individuallydf.plot(lw=0, marker=".", subplots=True, layout=(-1, 3), figsize=(15, 7.5), markersize=2)plt.tight_layout()plt.show();
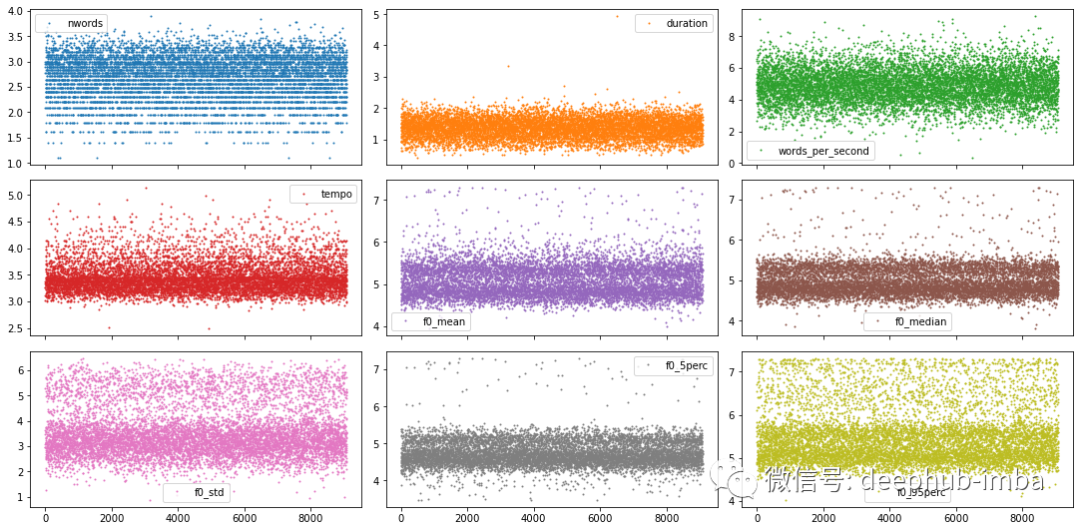
鉴于特征的数量很少,而且有相当漂亮的带有明显尾部的分布,可以遍历它们中的每一个,并逐个特征地确定异常值截止阈值。
2. 特征的相关性
下一步,看看所有特征之间的相关性。但在这样做之前需要对非数字目标特征进行编码。可以使用 scikit-learn 的 OrdinalEncoder 来执行此操作,但这可能会破坏年龄特征中的正确顺序。因此在这里手动进行映射。
import numpy as np
# Applies log1p on features that are not age, gender, filename or words_per_second
df = df.apply(
lambda x: np.log1p(x)
if x.name not in ["age", "gender", "filename", "words_per_second"]
else x)
# Let's look at the distribution once more
df.drop(columns=["age", "gender", "filename"]).hist(
bins=100, figsize=(14, 10))
plt.show();
现在可以使用 pandas 的 .corr() 函数和 seaborn 的 heatmap() 来更深入地了解特征相关性。
import seaborn as sns
plt.figure(figsize=(8, 8))
df_corr = df.corr() * 100
sns.heatmap(df_corr, square=True, annot=True, fmt=".0f", mask=np.eye(len(df_corr)), center=0)
plt.show();
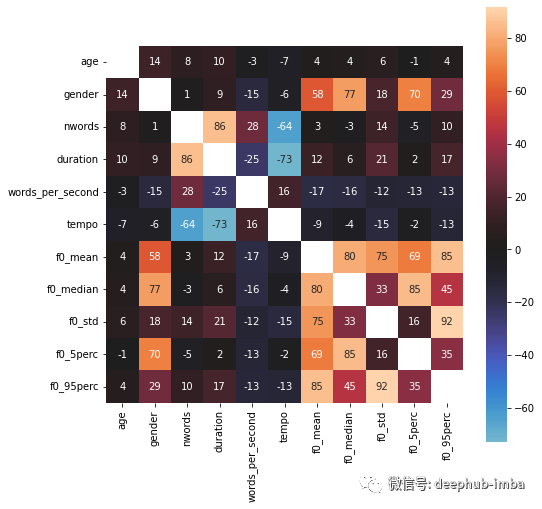
非常有趣!提取的 f0 特征似乎与性别目标有相当强的关系,而年龄似乎与任何其他的特征都没有太大的相关性。
3. 频谱图特征
目前还没有查看实际录音。正如之前看到的,有很多选择(即波形或 STFT、mel 或 mfccs 频谱图)。
音频样本的长度都不同,这意味着频谱图也会有不同的长度。因此为了标准化所有录音,首先要将它们剪切到正好 3 秒的长度:太短的样本会被填充,而太长的样本会被剪掉。
一旦计算了所有这些频谱图,我们就可以继续对它们执行一些 EDA!而且因为看到“性别”似乎与录音有特殊的关系,所以分别可视化两种性别的平均梅尔谱图,以及它们的差异。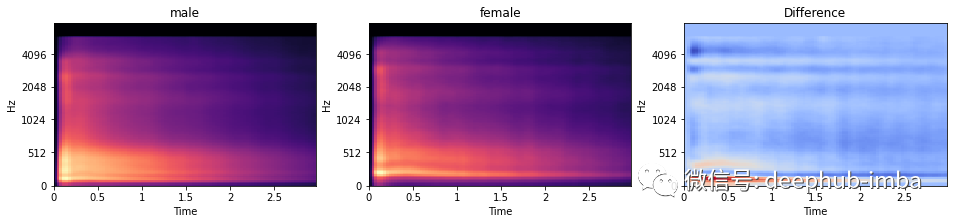
男性说话者的平均声音低于女性。这可以通过差异图中的较低频率(在红色水平区域中看到)的更多强度来看出。
模型选择
现在已经可以进行建模了。我们有多种选择。关于模型,我们可以:
训练我们经典(即浅层)机器学习模型,例如 LogisticRegression 或 SVC。
训练深度学习模型,即深度神经网络。
使用 TensorflowHub 的预训练神经网络进行特征提取,然后在这些高级特征上训练浅层或深层模型
而我们训练的数据是:
CSV 文件中的数据,将其与频谱图中的“mel 强度”特征相结合,并将数据视为表格数据集
单独的梅尔谱图并将它们视为图像数据集
使用TensorflowHub现有模型提取的高级特征,将它们与其他表格数据结合起来,并将其视为表格数据集
当然,有许多不同的方法和其他方法可以为建模部分创建数据集。因为我们没有使用全量的数据,所以在本文我们使用最简单的机器学习模型。
经典(即浅层)机器学习模型
这里使用EDA获取数据,与一个简单的 LogisticRegression 模型结合起来,看看我们能在多大程度上预测说话者的年龄。除此以外还使用 GridSearchCV 来探索不同的超参数组合,以及执行交叉验证。
from sklearn.linear_model import LogisticRegressionfrom sklearn.preprocessing import RobustScaler, PowerTransformer, QuantileTransformerfrom sklearn.decomposition import PCAfrom sklearn.pipeline import Pipelinefrom sklearn.model_selection import GridSearchCV
# Create pipelinepipe = Pipeline( [ ("scaler", RobustScaler()), ("pca", PCA()), ("logreg", LogisticRegression(class_weight="balanced")), ])
# Create gridgrid = { "scaler": [RobustScaler(), PowerTransformer(), QuantileTransformer()], "pca": [None, PCA(0.99)], "logreg__C": np.logspace(-3, 2, num=16),}
# Create GridSearchCVgrid_cv = GridSearchCV(pipe, grid, cv=4, return_train_score=True, verbose=1)
# Train GridSearchCVmodel = grid_cv.fit(x_tr, y_tr)
# Collect results in a DataFramecv_results = pd.DataFrame(grid_cv.cv_results_)
# Select the columns we are interested incol_of_interest = [ "param_scaler", "param_pca", "param_logreg__C", "mean_test_score", "mean_train_score", "std_test_score", "std_train_score",]cv_results = cv_results[col_of_interest]
# Show the dataframe sorted according to our performance metriccv_results.sort_values("mean_test_score", ascending=False)
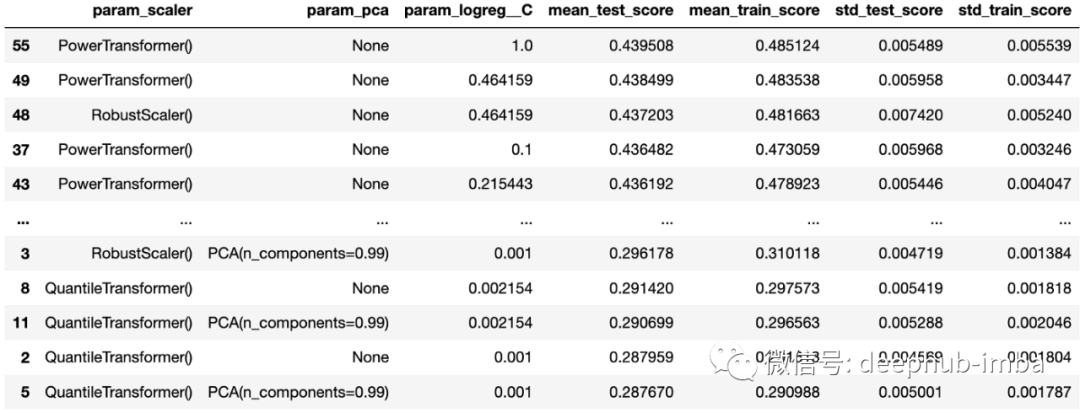
作为上述 DataFrame 输出的补充,还可以将性能得分绘制为探索的超参数的函数。但是因为使用了有多个缩放器和 PCA ,所以需要为每个单独的超参数组合创建一个单独的图。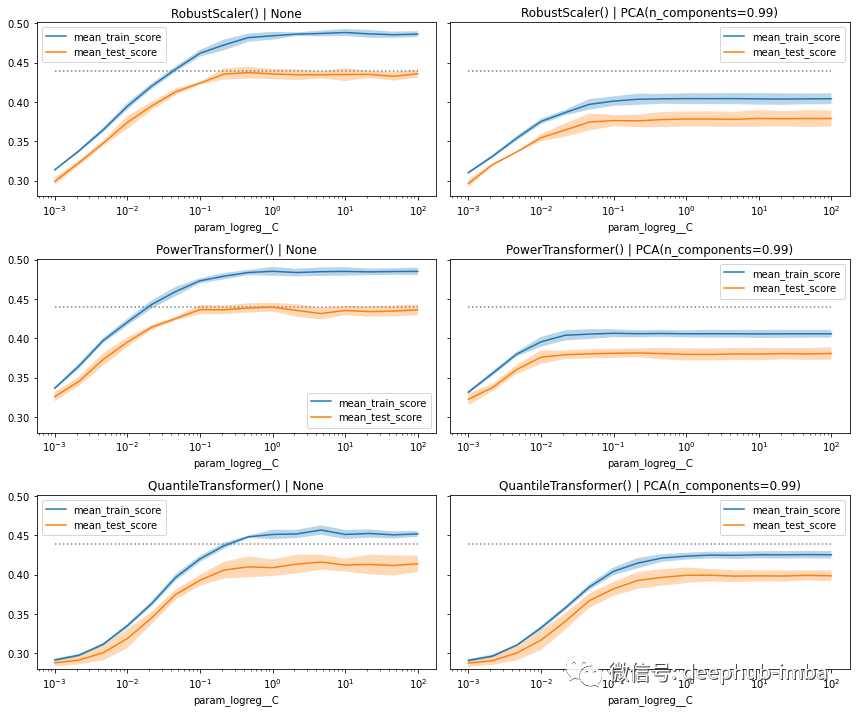
在图中,可以看到总体而言模型的表现同样出色。当降低 C 的值时,有些会出现更快的“下降”,而另一些则显示训练和测试(这里实际上是验证)分数之间的差距更大,尤其是当我们不使用 PCA 时。
下面使用 best_estimator_ 模型,看看它在保留的测试集上的表现如何。
# Compute score of the best model on the withheld test setbest_clf = model.best_estimator_best_clf.score(x_te, y_te)
>>> 0.4354094579008074
这已经是一个很好的成绩了。但是为了更好地理解分类模型的表现如何,可以打印相应的混淆矩阵。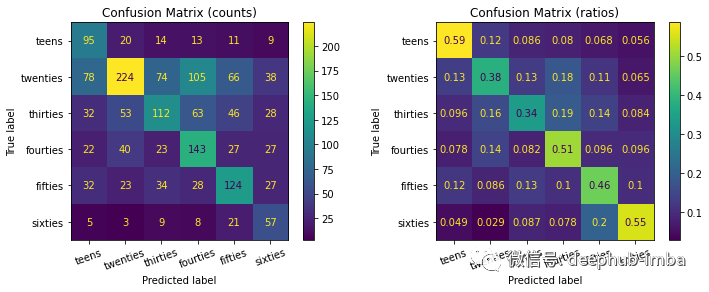
虽然该模型能够检测到比其他模型更多的 20 岁样本(左混淆矩阵),但总体而言,它实际上在对 10 岁和 60 岁的条目进行分类方面效果更好(例如,准确率分别为 59% 和 55%)。
总结
在这篇文章中,首先看到了音频数据是什么样的,然后可以将其转换成哪些不同的形式,如何对其进行清理和探索,最后如何将其用于训练一些机器学习模型。如果您有任何问题,请随时发表评论。
最后本文的源代码在这里下载:https://github.com/miykael/miykael.github.io/blob/master/assets/nb/04_audio_data_analysis/nb_audio_eda_and_modeling.ipynb作者:Michael Notter
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

