以下文章来源于NewBeeNLP ,作者上杉翔二
本篇博文梳理一篇knowledge-based方向的文章,结合了多模态知识的多模态知识图谱。来自复旦大学,先上路径:
- Title:Multi-Modal Knowledge Graph Construction and Application: A Survey
- Link:https://arxiv.org/abs/2202.05786v1
知识图谱到多模态知识图谱
首先知识图谱是一个以实体、概念为节点、以概念之间的各种语义关系为边的大规模语义网络。这种带有知识的结构也被广泛应用,但是,现有知识图谱都以纯文本的形式出现,却没有真实世界的连接。比如:
- 对抽象概念的理解。一个符号“dog”应该根植于物理世界,将其和真的狗之间建立联系对理解这些抽象概念是有效的。作者同时也举例了“Hand-in-waistcoat”等词汇。
- 对特定任务的帮助。在关系提取任务中,额外的图像会以在视觉上帮助区分属性和关系,如partOf (键盘和屏幕是笔记本电脑的一部分),colorOf(香蕉通常是黄色或黄绿色,而无蓝色的)。在文本生成任务中,可以帮助生成一个信息更丰富的实体级句子(例如特朗普正在发表演讲),而不是一个模糊的概念级描述(例如一个金发高个子男人正在发表演讲)。
因此多模态知识图谱(Multi-Modal Knowledge Graph,MMKG)被逐渐瞩目,这篇文章主要关注两个话题:
- 构建(Construction)。MMKG的构建主要有两种:一种是从图像到符号(from images to symbols),即用KG表示符号来标注图像;另一种是从符号到图像( from symbols to images),即把KG中的符号对应到图像。
- 应用(Application)。MMKG的应用也可以大致分为两类,一类是In-MMKG应用,目的是解决MMKG本身的质量或集成问题;另一类是 Out-of-MMKG应用,作者指的是如果将MMKG应用到一般的多模态任务中。
多模态知识图谱的好处
- MMKG提供了足够的背景知识来丰富实体和概念的表示,特别是对于长尾问题,引入辅助的常识知识可以增强图像和文本的表示能力。
- MMKG能够理解图像中不可见的物体。这主要是利用符号知识提供的在视觉上看不见物体的符号信息,或在看不见物体和看不见物体之间建立语义关系。
- MMKG支持多模态推理。在外部知识资源的帮助下,VQA任务的推理能力可以得到提升。
- MMKG通常提供多模态数据作为附加特性来弥补一些NLP任务中的信息差距。以实体识别为例,一个图像可以提供足够的信息来识别“Rocky”是一只狗的名字还是一个人的名字。
多模态知识图谱构建
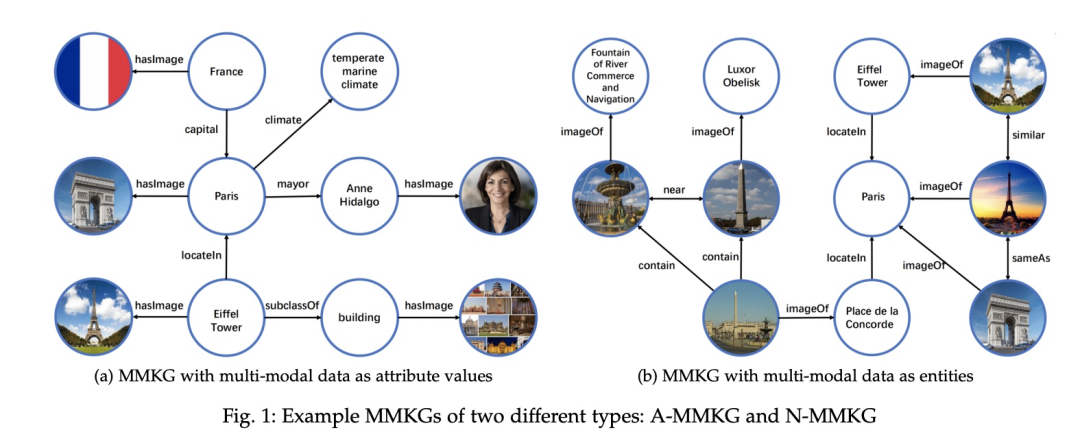
MMKG构建需要将普通KG中的符号知识(包括实体、概念、关系等)与图像关联起来。MMKG按类型可分为两种,A-MMKG和N-MMKG。A即 attribute,将多模态数据如图像作为实体或概念的特定属性值,而N即entities,将多模态数据直接作为KGs中的实体。
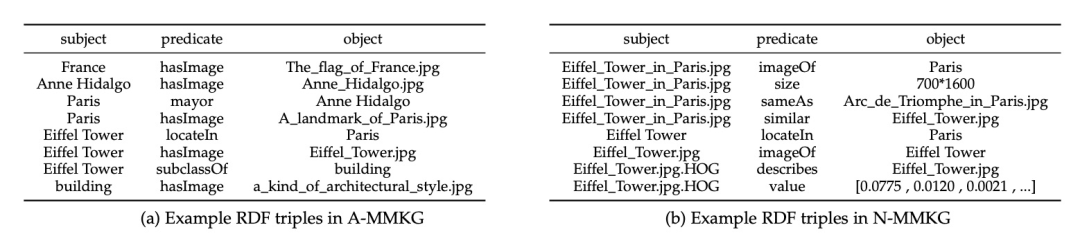
下图是两种类型的主要predicate,如在A-MMKG中hasImage,N-MMKG的sameAs。
在构建上,上面也提到过的,主要有两种方式
(1) from images to symbols,即在图像上标注KG中的符号;(2) from symbols to images,即在图像上标注KG中的对应符号。
下图a是第一种靠 labeling images构建的方法,图b是第二种 symbol grounding的构建方式的流行数据集们。
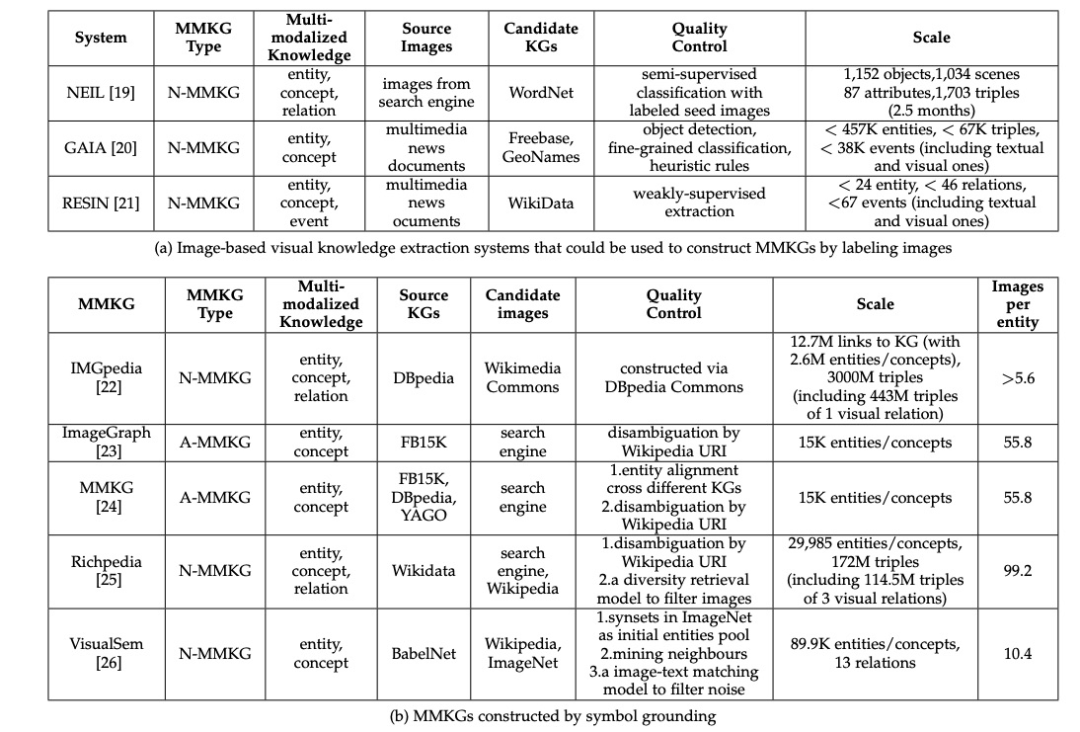
从图像到符号:标注图像(labeling images)
可以由人工标注的数据集来监督,让人画出边界框并标注带有给定标签的图像或图像区域。也可搭建一个系统来做,比如分为三个子任务:视觉实体/概念提取、视觉关系提取和视觉事件提取。
- 视觉实体/概念提取的目的是检测和定位图像中的目标视觉对象,然后用KG中的实体/概念符号标记这些对象,目标检测和视觉定位使用较多;
- 视觉关系提取的目的是识别图像中检测到的视觉实体/概念之间的语义关系,然后用KG中的关系对其进行标记,其中基于规则、统计或者更细粒度的方法较多;
- 事件提取任务的目的是预测事件类型。
从符号到图像:符号定位( symbol grounding)
主要寻找合适的图像来表示传统KG中已经存在的符号。与图像标注方式相比,这种方式在MMKG构建中更为广泛,主要分为几个过程:实体定位、概念定位和关系定位。
- 对于找实体图像来说,基于百科或搜索是常见的方式
- 对于概念来说,该概念是否可以被可视化,和如何从大量图片中选择有代表性、多样性的图片是重要话题;
- 对于关系定位来说,图文匹配或图匹配会是比较好的选择。
作者对这两块儿会遇到的挑战和未来的优化机会做了详细的探讨,有兴趣可以拜读原文。与此同时,如何应用好这些已经被制作完善的MMKG也很重要。
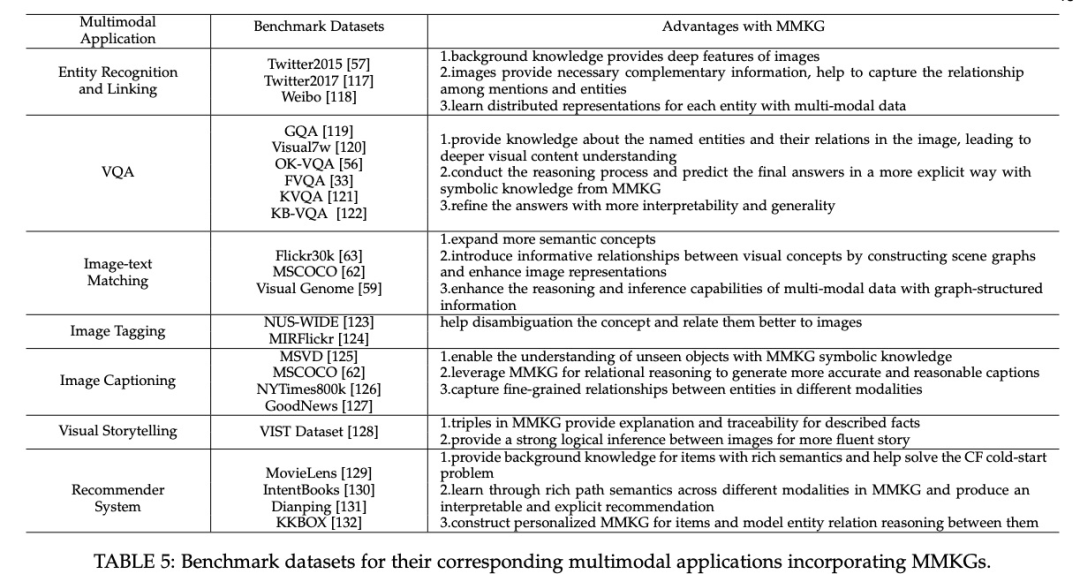
多模态知识图谱应用
应用任务主要分为in-KG和out-of-KG。In-MMKG应用是指在MMKG本身内进行的任务,如:链接预测Link Prediction,三元组分类Triple Classification,实体链接Entity Classification,实体对齐Entity Alignment等等。这些和KG中已经探讨很多的任务,本篇博文就不再赘述太多。
Out-of-MMKG则是更为广泛一些的下游任务,如多模态实体识别与链接Multi-modal Entity Recognition and Linking,视觉问答 Visual Question Answering,图像文本匹配Image-Text Matching,多模态生成任务Multi-modal Generation Tasks,多模态推荐系统Multi-modal Recommender System。
- Multi-modal Entity Recognition and Linking。图像可以为实体识别提供必要的互补信息。主要通过两种方式利用MMKG中的图像知识:1)提供实体应该链接的目标实体;2)学习每个多模态数据的分布式表示,然后用它来度量相关性。
- Visual Question Answering。MMKG可以提供关于问题实体及其在图像中的关系的知识,从而带来更深层次的视觉内容理解,同时MMKG中的结构化符号知识都可以为进行推理过程和预测最终答案的一种更明确的方式。
- Image-Text Matching。MMKG可以利用多模态实体之间的关系来扩展更多的视觉和语义概念。此外MMKG还可以帮助构建场景图,引入视觉概念之间的信息相关知识,进一步增强图像表示。
- Multi-modal Generation Tasks。包括 image tagging, image captioning, visual storytelling都算,MMKG中的概念知识可以极大地提高图像的表示能力,在解决歧义、看不见的物体、词汇量等方面都表现强大。
- Multi-modal Recommender System。利用外部MMKG来获得具有丰富语义的item表示,甚至个性化的表示都完全可以,这一点在KG in Recommendation就很有效,扩展到多模态形式或许能进一步增强效果。
多模态知识图谱开放问题
作者主要提了以下未来的开放性问题:
- 复杂符号知识定位(Grounding Complex Symbolic Knowledge Grounding)。即除了实体、概念和关系的基础之外,一些下游应用还需要复杂的符号知识的基础,如KG中的一条路径、一个子图等涉及到多重关系。且在许多情况下,多重关系的复合语义是隐式表达的且可能随着时间而改变。
- 质量控制(Quality Control)。大规模的MMKG可能存在错误、缺少事实或过时的事实,因此精度、完整性、一致性和新鲜度,图像质量等可能都需要被讨论。
- 效率(Efficiency)。MMKG的构造效率问题较大,如NEIL需要大约350K CPU hours来为2273个对象收集400K的可视化实例,而在一个典型的KG中,这个数量会变成数十亿个实例。而如果继续扩展到视频数据,这个扩展性问题会继续被放大。除了MMKG的构建,MMKG的在线应用的要求也会更高。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

