时态差分法(Temporal Difference, TD)是一类在强化学习中广泛应用的算法,用于学习价值函数或策略。Sarsa和Q-learning都是基于时态差分法的重要算法,用于解决马尔可夫决策过程(Markov Decision Process, MDP)中的强化学习问题。
下面是最简单的TD方法更新:
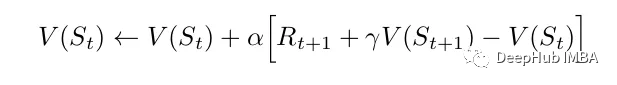
它只使用当前行动之后的奖励值和下一个状态的值作为目标。Sarsa(State-Action-Reward-State-Action)和Q-learning是都是基于时态差分法的强化学习方法。
Sarsa和Q-learning的区别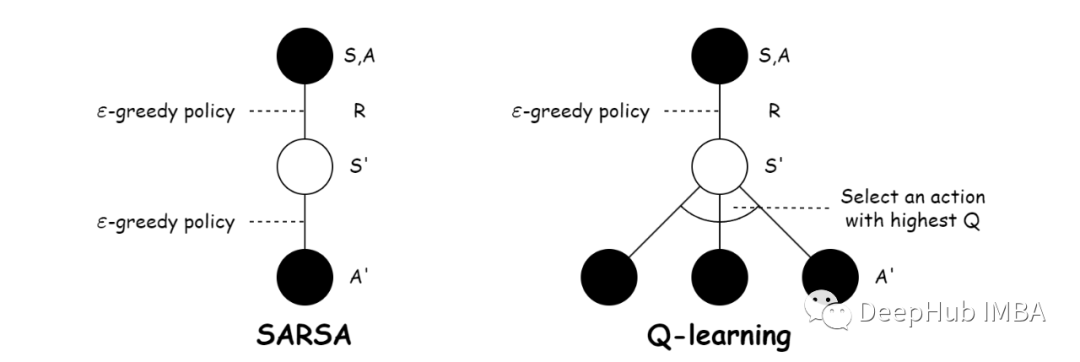
Sarsa代表State-Action-Reward-State-Action。是一种基于策略的方法,即使用正在学习的策略来生成训练数据。Q-learning是一种非策略方法它使用不同的策略为正在学习的值函数的策略生成训练数据。
Sarsa的更新规则如下:
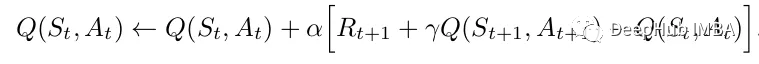
其中:
a' 是在新状态s'下选择的下一个动作。
Q-learning是另一种基于时态差分法的增强学习算法,用于学习一个值函数,表示在状态s下采取最优动作得到的期望累积奖励。Q-learning的更新规则如下:
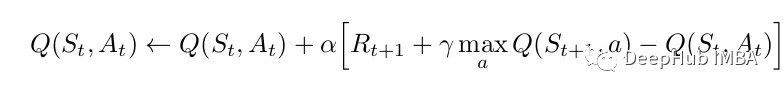
其中:max(Q(s', a')) 表示在新状态s'下选择下一个动作a'时的最大值函数估计。
从上面的更新可以看出这两个方法非常相似,主要区别在于它们的更新策略。在Sarsa中,更新策略考虑了在新状态下采取的下一个动作,而在Q-learning中,更新策略总是选择了新状态下使值函数最大化的动作。因此,Sarsa更倾向于跟随当前策略进行学习,而Q-learning更倾向于学习最优策略。
cliff walking环境下的表现这是RL书中描述的一个简单环境,如下面的截图所示。
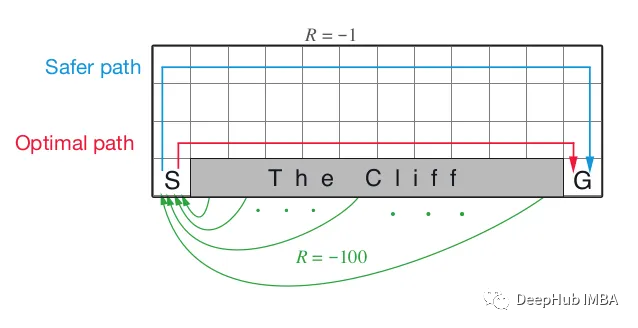
红色路径是最优的,但它是非常危险的,因为代理可能会发现自己在悬崖边缘。
从环境的描述来看,代理的目标是最大化累积奖励,即采取尽可能少的步数,因为每一步的值为-1。最优路径是悬崖上方的那条,因为它只需要13步,值为-13。我使用上面的2td(0)方法来确定它们是否在上面以获得最优路径。
实验环境如下:
在训练中使用以下超参数:
Epsilon: 0.1, 选择具有相同概率的所有动作的概率,用于ε贪婪算法。
结果:
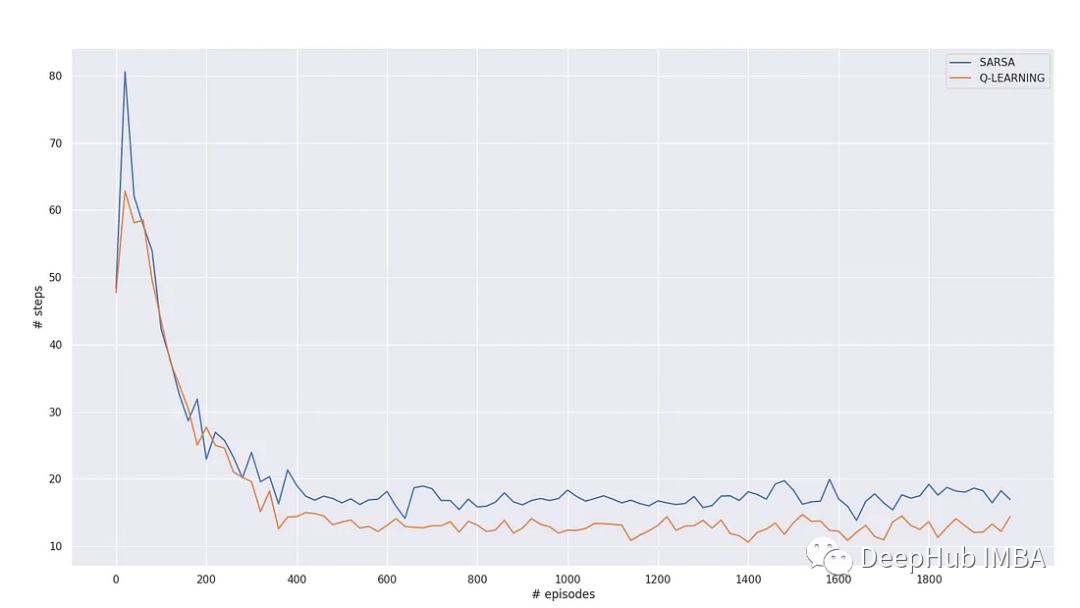
Sarsa和Q-learning在收敛的时间上大致相同,但Q-learning能够学习13个步骤的最优路径。Sarsa无法学习最优路径,它会选择避开悬崖。这是因为它的更新函数是使用贪婪的方式来获取下一个状态-动作值,因此悬崖上方的状态值较低。
Q-learning在更新中使用了下一个状态动作值的最大值,因此它能够小心地沿着边缘移动到目标状态G。下图显示了每个训练论测的学习步骤数量。为了使图表更加平滑,这里将步骤数按20个一组取平均值。我们可以清楚地看到,Q-learning能够找到最优路径。
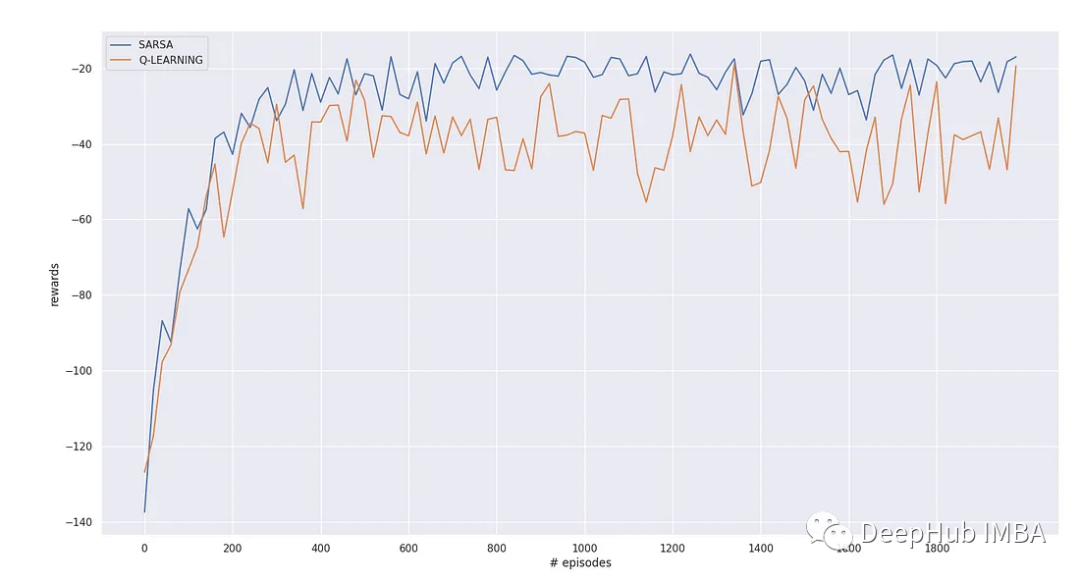
下图显示了2种算法的在线性能*这些值再次以20组为单位进行平均)。我们可以看到,Sarsa的性能比Q-learning更好。这是因为随着Q-learning学习获得最优路径,偶尔会发现自己陷入绝境,因为要更新的状态动作对的生成遵循了贪婪算法。而Sarsa学会了避开靠近悬崖的状态,从而减少了靠近悬崖的机会。
这个简单的例子说明了Sarsa和Q-learning之间的比较,我们总结两个算法的区别:
Sarsa和Q-learning都是基于时态差分法的强化学习算法,它们在解决马尔可夫决策过程(MDP)中的强化学习问题时有一些重要的区别。
更新策略:
Q-learning:Q-learning的更新策略是"状态-动作-奖励-最大值动作",即更新后的动作是在新状态下具有最大值函数估计的动作。这使得Q-learning更加倾向于学习最优策略,但也可能导致其学习过程不稳定,容易受到噪声干扰。
学习方式:
Q-learning:Q-learning更倾向于学习最优策略,但由于其更新策略不考虑实际执行的下一个动作,可能在一些情况下收敛更快,但也更容易受到噪声的影响。
探索策略:
Q-learning:Q-learning在更新时不受当前策略的影响,更容易在学习过程中进行探索。然而,这种无关探索策略可能导致Q-learning在某些情况下过度探索,陷入不收敛的状态。
应用场景:
Q-learning:适用于倾向于学习最优策略的任务,或者在需要快速收敛时的情况。
这两种算法只是强化学习领域众多算法中的两种,还有其他更高级的算法如Deep Q Network (DQN)、Actor-Critic等,可以根据问题的复杂度和要求选择适当的算法。
最后如果你想自行进行试验,这里是本文两个试验的源代码:
https://github.com/mirqwa/reinforcement-leaning
作者:Kim Rodgers
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。



